本文[1]结合 Semantic SLAM 与 Learning-based 3D Det 技术,提出了一种用于自动驾驶的动态目标定位与本车状态估计的方法。本文系统性较强,集成了较多成熟的模块,对工程应用也有较强的指导意义。  如图 1. 所示,整个系统框架由三部分组成:
如图 1. 所示,整个系统框架由三部分组成:
- 2D object detection and viewpoint classification,目标位姿通过 2D-3D 约束求解出来;
- feature extraction and matching,双目及前后帧的特征提取与匹配;
- ego-motion and object tracking,将语义信息及特征量加入到优化中,并且加入车辆动力学约束以获得平滑的运动估计。
1. Viewpoint Classification and 3D Box Inference
1.1. Viewpoint Classification
选用 Faster R-CNN 作为 2D 检测框架,在此基础上,加入车辆视野(viewpoint)分类分支。由图 2. 所示,水平视野分为八类,垂直视野分为两类,总共 16 类。 
1.2. 3D Box Inference Based on Viewpoint
网络输出图像 2D 框以及目标车辆的视野类别(viewpoint),此时我们假设:
- 2D 框准确;
- 每种车辆的尺寸相同;
- 2D 框能紧密包围 3D 框;
在以上假设条件下,我们可以求得 3D 框,该 3D 框作为后续优化的初始值。约束方程的表示在论文中比较晦涩,在这里我做细致的推倒。 3D 框可表示为 \(\{x,y,z,\theta,w,h,l\}\),其中 \(\{w,h,l\}\) 分别对应 \({x,y,z}\) 维度。如图 2.(b) 所示,这个视角下,四个 3D 框的顶点,可得四个约束方程。推倒过程为: \[\require{cancel} \begin{bmatrix} u_{min}\\ v_1\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{1}^{cam}\\ y_{1}^{cam}\\ z_{1}^{cam}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{1}^{obj}\\ y_{1}^{obj}\\ z_{1}^{obj}\\ \end{bmatrix}=\begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} \frac{w}{2}\\ \frac{h}{2}\\ \frac{l}{2}\\ \end{bmatrix}\] 其中 \(K\) 为相机内参,做归一化处理消去;\(T_{cam}^{obj}\) 为目标中心坐标系在相机坐标系下的表示,\((\cdot)^{cam/obj}\) 分别为点在相机坐标系,目标中心坐标系下的表示。同样的,这个视野下,②,③,④ 点都可以由此获得: \[\left\{\begin{array}{l} \require{cancel} \begin{bmatrix} u_{min}\\ v_1\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{1}^{cam}\\ y_{1}^{cam}\\ z_{1}^{cam}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{1}^{obj}\\ y_{1}^{obj}\\ z_{1}^{obj}\\ \end{bmatrix}=\begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} \frac{w}{2}\\ \frac{h}{2}\\ \frac{l}{2}\\ \end{bmatrix}\\ \begin{bmatrix} u_{max}\\ v_2\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{2}^{cam}\\ y_{2}^{cam}\\ z_{2}^{cam}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{2}^{obj}\\ y_{2}^{obj}\\ z_{2}^{obj}\\ \end{bmatrix}=\begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} -\frac{w}{2}\\ \frac{h}{2}\\ -\frac{l}{2}\\ \end{bmatrix}\\ \begin{bmatrix} u_3\\ v_{min}\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{3}^{cam}\\ y_{3}^{cam}\\ z_{3}^{cam}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{3}^{obj}\\ y_{3}^{obj}\\ z_{3}^{obj}\\ \end{bmatrix}=\begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} \frac{w}{2}\\ -\frac{h}{2}\\ -\frac{l}{2}\\ \end{bmatrix}\\ \begin{bmatrix} u_4\\ v_{max}\\ 1\\ \end{bmatrix}=K\cdot \begin{bmatrix} x_{4}^{cam}\\ y_{4}^{cam}\\ z_{4}^{cam}\\ \end{bmatrix}\doteq \xcancel{K} \cdot T_{cam}^{obj} \cdot \begin{bmatrix} x_{4}^{obj}\\ y_{4}^{obj}\\ z_{4}^{obj}\\ \end{bmatrix}=\begin{bmatrix} x\\ y\\ z\\ \end{bmatrix}+ \begin{bmatrix} cos\theta & 0 &sin\theta\\ 0 & 1 & 0\\ -sin\theta & 0 & cos\theta\\ \end{bmatrix} \cdot \begin{bmatrix} -\frac{w}{2}\\ \frac{h}{2}\\ \frac{l}{2}\\ \end{bmatrix} \end{array}\right.\]
将 \(z\) 方向归一化后,进一步得到最终的四个约束式子: \[\left\{\begin{array}{l} u_{min}=(x+ \frac{w}{2} cos\theta+ \frac{l}{2} sin\theta) / (z- \frac{w}{2} sin\theta + \frac{l}{2} cos\theta)\\ u_{max}=(x- \frac{w}{2} cos\theta- \frac{l}{2} sin\theta) / (z+ \frac{w}{2} sin\theta - \frac{l}{2} cos\theta)\\ v_{min}=(y- \frac{h}{2}) / (z- \frac{w}{2} sin\theta - \frac{l}{2} cos\theta)\\ v_{max}=(y+ \frac{h}{2}) / (z+ \frac{w}{2} sin\theta + \frac{l}{2} cos\theta) \end{array}\right.\] 以上四个方程可以闭式求解 3D 框 \({x,y,z,}\)。该方法将 3D 框的回归求解分解成了 2D 框回归,视野角分类以及解方程组的过程,强依赖于前面的三点假设,实际情况 3D 框与 2D 框不会贴的很紧。这个 3D 框结果只用来作后续的特征提取区域及最大后验概率估计的初始化。
2. Feature Extraction and Matching
这一部分做的是左右目及前后帧特征提取及匹配。选用 ORB 特征,目标区域由投影到图像的 3D 框确定。
- 目标区域内左右目的立体匹配 由于已知目标的距离及尺寸,所以只需要在一定小范围内进行特征点的行搜索匹配。
- 目标及背景区域下前后帧的时序匹配 首先进行 2D 框的关联,2D 框经过相机旋转补偿后,最小化关联框的中心点距离及框形状相似度值。然后在关联上的目标框区域以及背景区域里,分别作 ORB 特征的匹配,异常值在 RANSAC 下通过基础矩阵测试去除。
3. Ego-motion and Object Tracking
首先进行本车运动状态估计,可在传统 SLAM 框架下做,不同的是将动态障碍物中的特征点去除。有了本车的位姿后,再估计动态障碍物的运动状态。文中符号定义较为复杂,这里不做赘述。
3.1. Ego-motion Tracking
给定左目前后帧背景区域特征点的观测,本车状态估计可以通过极大似然估计(Maximum Likelihood Estimation)得到。MLE 可以转化为非线性最小二乘问题,也就是 Bundle Adjustment 过程,这是典型的 SLAM 问题。文中给出的误差方程: 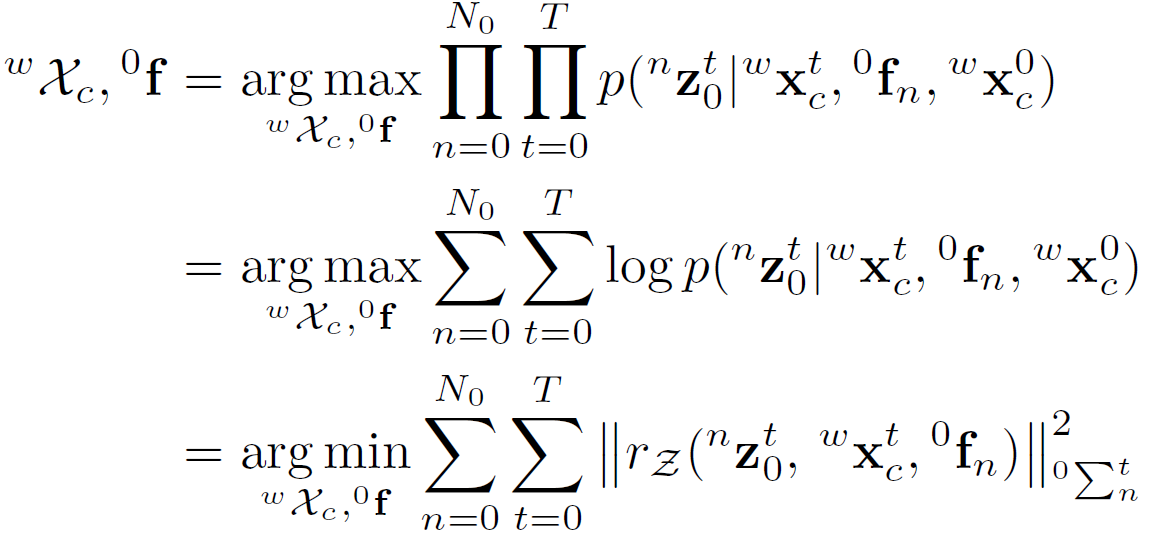 需要求解的是本车位姿以及背景特征点坐标,这是后验概率,可转为似然函数求解,然后转化为非线性优化问题。可参考《视觉 SLAM 十四讲》(107-108)来理解。
需要求解的是本车位姿以及背景特征点坐标,这是后验概率,可转为似然函数求解,然后转化为非线性优化问题。可参考《视觉 SLAM 十四讲》(107-108)来理解。
3.2. Semantic Object Tracking
得到本车相机的位姿后,运动目标的状态估计可以通过最大后验概率估计(Maximum-a-posterior, MAP)得到。类似的,可转为非线性优化问题进行求解,联合优化每个车辆的位姿,尺寸,速度,方向盘转角,所有特征点 3D 位置。有四个 loss 项: 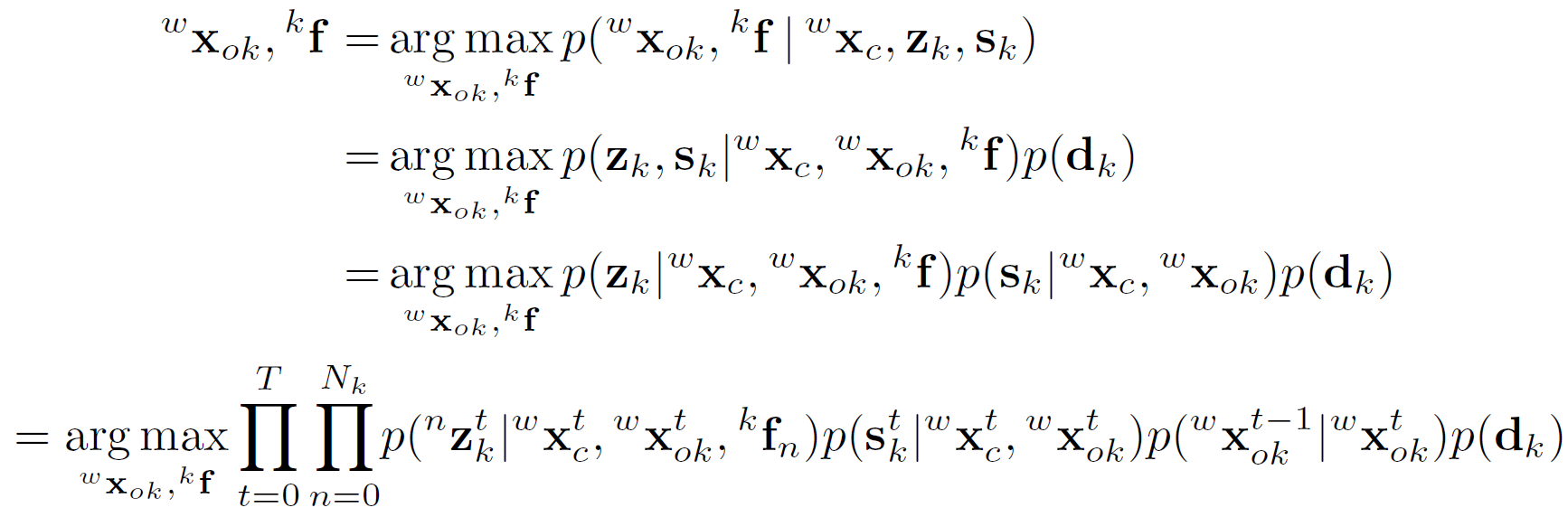
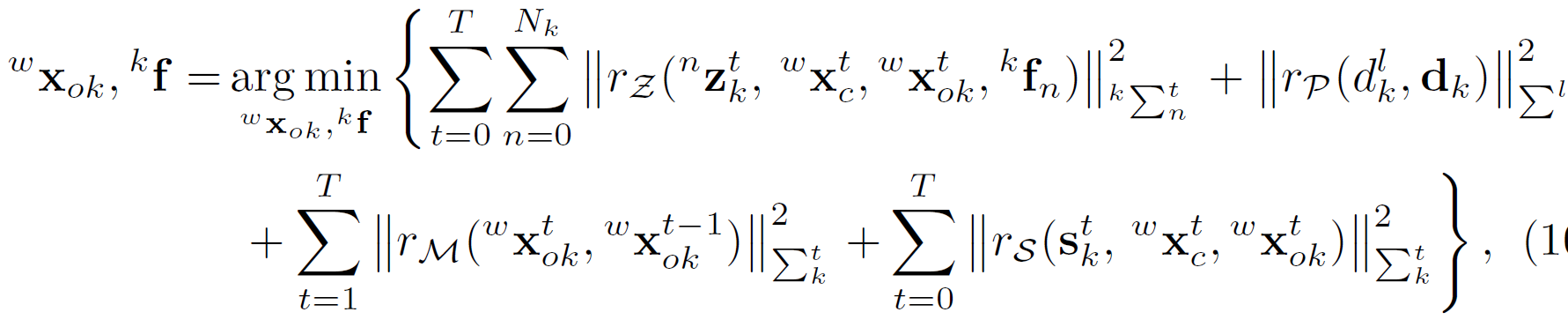 \(r_Z,r_P,r_M,r_S\) 分别代表:
\(r_Z,r_P,r_M,r_S\) 分别代表:
- Sparse Feature Observation
目标上的特征点重投影到左右目图像的误差,注意有左右目两个误差项; - Semantic 3D Object Measurement
3D 框投影到图像上与 2D 框的尺寸约束投影误差,即 1.2 节中的形式,区别在车辆尺寸与位姿作为了优化项; - Vehicle Motion Model
对于车辆,前后时刻的状态要有连续性,即误差最小; - Point Cloud Alignment
为了减少 3D 框的整体偏移,引入特征点到 3D 观察面的最小距离误差;
这里只对车辆运动模型进行分析,其它几项基本在前文已经有描述或者比较常识化,就不展开,具体公式可参见论文。
由实验可知 Sparse Feature Observation 与 Point Cloud Alignment 对性能提升较明显,Motion Model 对困难情景性能才有提升。
3.2.1. Vehicle Motion Model
[2] 中介绍了前转向车的两种模型:运动学模型(Kinematic Bicycle Model),以及更复杂的动力学模型(Dynamic Bicycle Model)。运动学模型假设车辆不存在滑动,这在大多数情况下都是满足的,所以我们只介绍运动学模型。  如图 3. 所示,前后轮无滑动的约束下,可得方程组: \[\left\{\begin{array}{rl}
\dot{x}_fsin(\theta+\delta)-\dot{y}_fcos(\theta+\delta)=&0\\
\dot{x}sin(\theta)-\dot{y}cos(\theta)=&0\\
x+Lcos(\theta)=&x_f \quad\Rightarrow \quad \dot{x}-\dot{\theta}Lsin(\theta)=\dot{x}_f\\
y+Lsin(\theta)=&y_f \quad\Rightarrow \quad \dot{y}+\dot{\theta}Lcos(\theta)=\dot{y}_f
\end{array}\right.\] 由此可得到: \[\dot{x}sin(\theta+\delta)-\dot{y}cos(\theta+\delta)-\dot{\theta}Lcos(\delta)=0\] 用 \(\left(v \cdot cos(\theta),v\cdot sin(\theta)\right)\) 代替 \((\dot{x},\dot{y})\) 可得: \[\dot{\theta}=\frac{tan(\delta)}{L}\cdot v\] 最终可整理成矩阵形式: \[
\begin{bmatrix}
\dot{x}\\
\dot{y}\\
\dot{\theta}\\
\dot{\delta}\\
\dot{v}\\
\end{bmatrix}=
\begin{bmatrix}
0 &0 &0 &0 &cos(\theta)\\
0 &0 &0 &0 &sin(\theta)\\
0 &0 &0 &0 &\frac{tan(\delta)}{L}\\
0 &0 &0 &0 &0\\
0 &0 &0 &0 &0\\
\end{bmatrix}
\begin{bmatrix}
x\\
y\\
\theta\\
\delta\\
v\\
\end{bmatrix}+
\begin{bmatrix}
0 &0\\
0 &0\\
0 &0\\
1 &0\\
0 &1\\
\end{bmatrix}
\begin{bmatrix}
\gamma\\
\alpha\\
\end{bmatrix}
\] 其中 \(L\) 为车辆参数。观测量有:
如图 3. 所示,前后轮无滑动的约束下,可得方程组: \[\left\{\begin{array}{rl}
\dot{x}_fsin(\theta+\delta)-\dot{y}_fcos(\theta+\delta)=&0\\
\dot{x}sin(\theta)-\dot{y}cos(\theta)=&0\\
x+Lcos(\theta)=&x_f \quad\Rightarrow \quad \dot{x}-\dot{\theta}Lsin(\theta)=\dot{x}_f\\
y+Lsin(\theta)=&y_f \quad\Rightarrow \quad \dot{y}+\dot{\theta}Lcos(\theta)=\dot{y}_f
\end{array}\right.\] 由此可得到: \[\dot{x}sin(\theta+\delta)-\dot{y}cos(\theta+\delta)-\dot{\theta}Lcos(\delta)=0\] 用 \(\left(v \cdot cos(\theta),v\cdot sin(\theta)\right)\) 代替 \((\dot{x},\dot{y})\) 可得: \[\dot{\theta}=\frac{tan(\delta)}{L}\cdot v\] 最终可整理成矩阵形式: \[
\begin{bmatrix}
\dot{x}\\
\dot{y}\\
\dot{\theta}\\
\dot{\delta}\\
\dot{v}\\
\end{bmatrix}=
\begin{bmatrix}
0 &0 &0 &0 &cos(\theta)\\
0 &0 &0 &0 &sin(\theta)\\
0 &0 &0 &0 &\frac{tan(\delta)}{L}\\
0 &0 &0 &0 &0\\
0 &0 &0 &0 &0\\
\end{bmatrix}
\begin{bmatrix}
x\\
y\\
\theta\\
\delta\\
v\\
\end{bmatrix}+
\begin{bmatrix}
0 &0\\
0 &0\\
0 &0\\
1 &0\\
0 &1\\
\end{bmatrix}
\begin{bmatrix}
\gamma\\
\alpha\\
\end{bmatrix}
\] 其中 \(L\) 为车辆参数。观测量有:
- \((x,y,\theta)\) 为车辆的位置及朝向角;
- \(\delta\) 为方向盘/车轮转角;
- \(v\) 为车辆速度;
控制量有:
- \(\gamma\) 为方向盘角度比率;
- \(\alpha\) 为加速度;
本文的目的是要约束车辆时序上运动(速度及朝向)的平滑一致性,令控制量 \(\gamma,\alpha\) 为 0,然后可得状态量在相邻时刻的关系应满足: \[\left\{\begin{array}{l}
\hat{x}^t=x^{t-1}+cos(\theta^{t-1})v^{t-1}\Delta t\\
\hat{y}^t=y^{t-1}+sin(\theta^{t-1})v^{t-1}\Delta t\\
\hat{\theta}^t=\theta^{t-1}+\frac{tan(\delta^{t-1})}{L}v^{t-1}\Delta t\\
\hat{\delta}^t=\delta^{t-1}\\
\hat{v}^t=v^{t-1}
\end{array}\right.\] 由此可整理成论文中矩阵的形式及误差项: 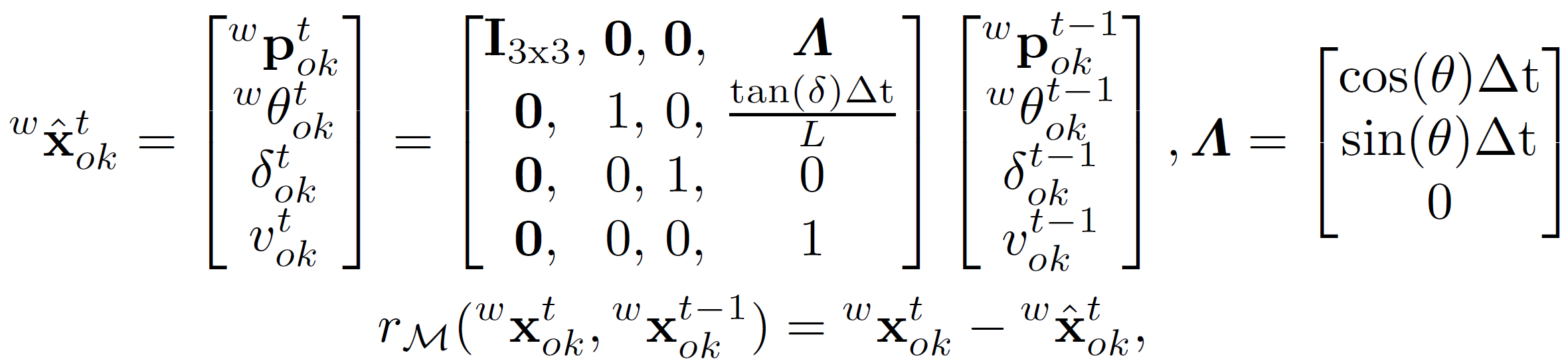
[1] Li, Peiliang, and Tong Qin. "Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving." Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[2] Gu, Tianyu. Improved trajectory planning for on-road self-driving vehicles via combined graph search, optimization & topology analysis. Diss. Carnegie Mellon University, 2017.
